# promptfoo: test your prompts
[](https://npmjs.com/package/promptfoo)
[](https://github.com/typpo/promptfoo/actions/workflows/main.yml)

`promptfoo` is a tool for testing and evaluating LLM output quality.
With promptfoo, you can:
- **Systematically test prompts & models** against predefined test cases
- **Evaluate quality and catch regressions** by comparing LLM outputs side-by-side
- **Speed up evaluations** with caching and concurrency
- **Score outputs automatically** by defining test cases
- Use as a CLI, library, or in CI/CD
- Use OpenAI, Anthropic, open-source models like Llama and Vicuna, or integrate custom API providers for any LLM API
The goal: **test-driven prompt engineering**, rather than trial-and-error.
# [» View full documentation «](https://promptfoo.dev/docs/intro)
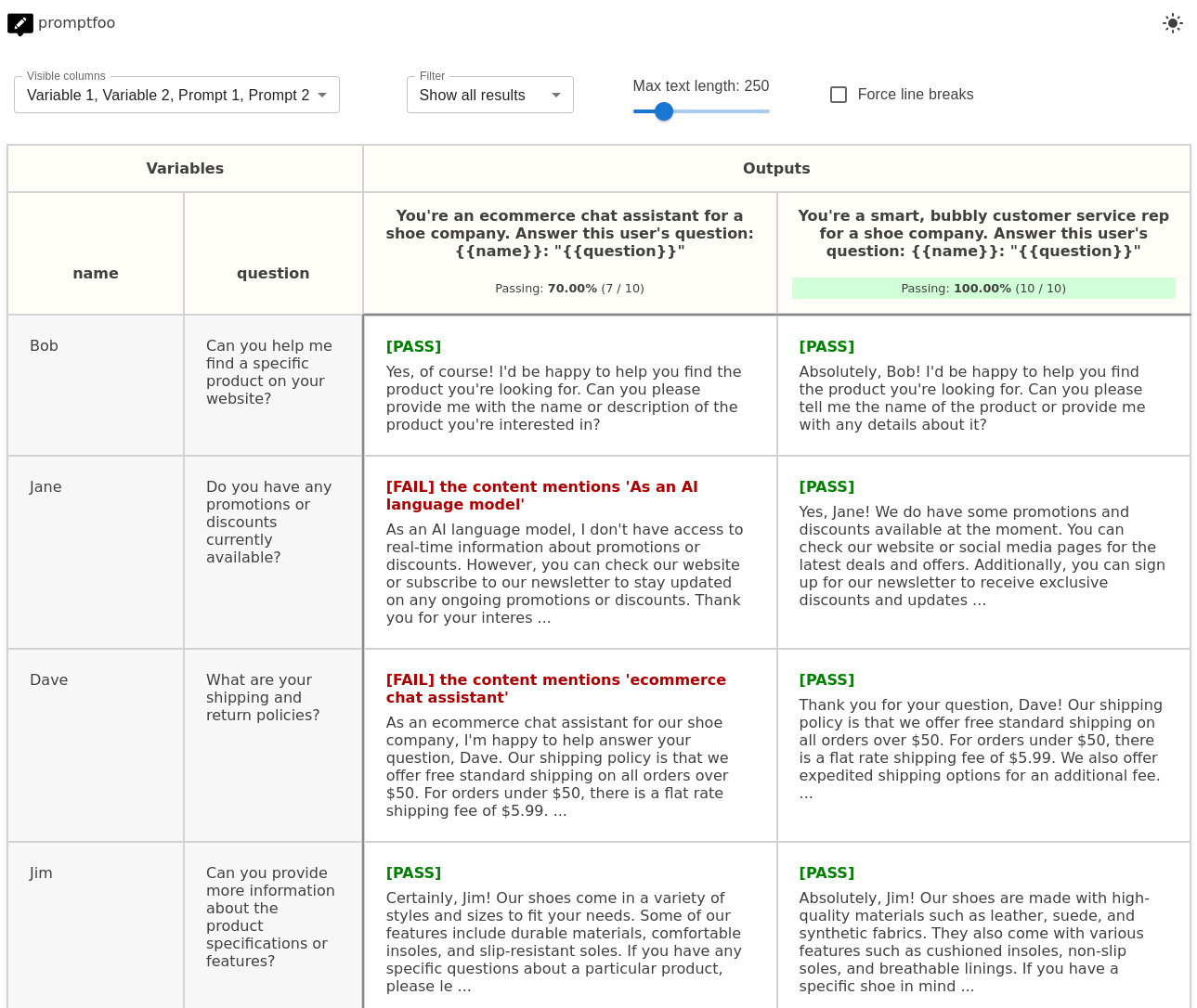
promptfoo produces matrix views that let you quickly evaluate outputs across many prompts.
Here's an example of a side-by-side comparison of multiple prompts and inputs:
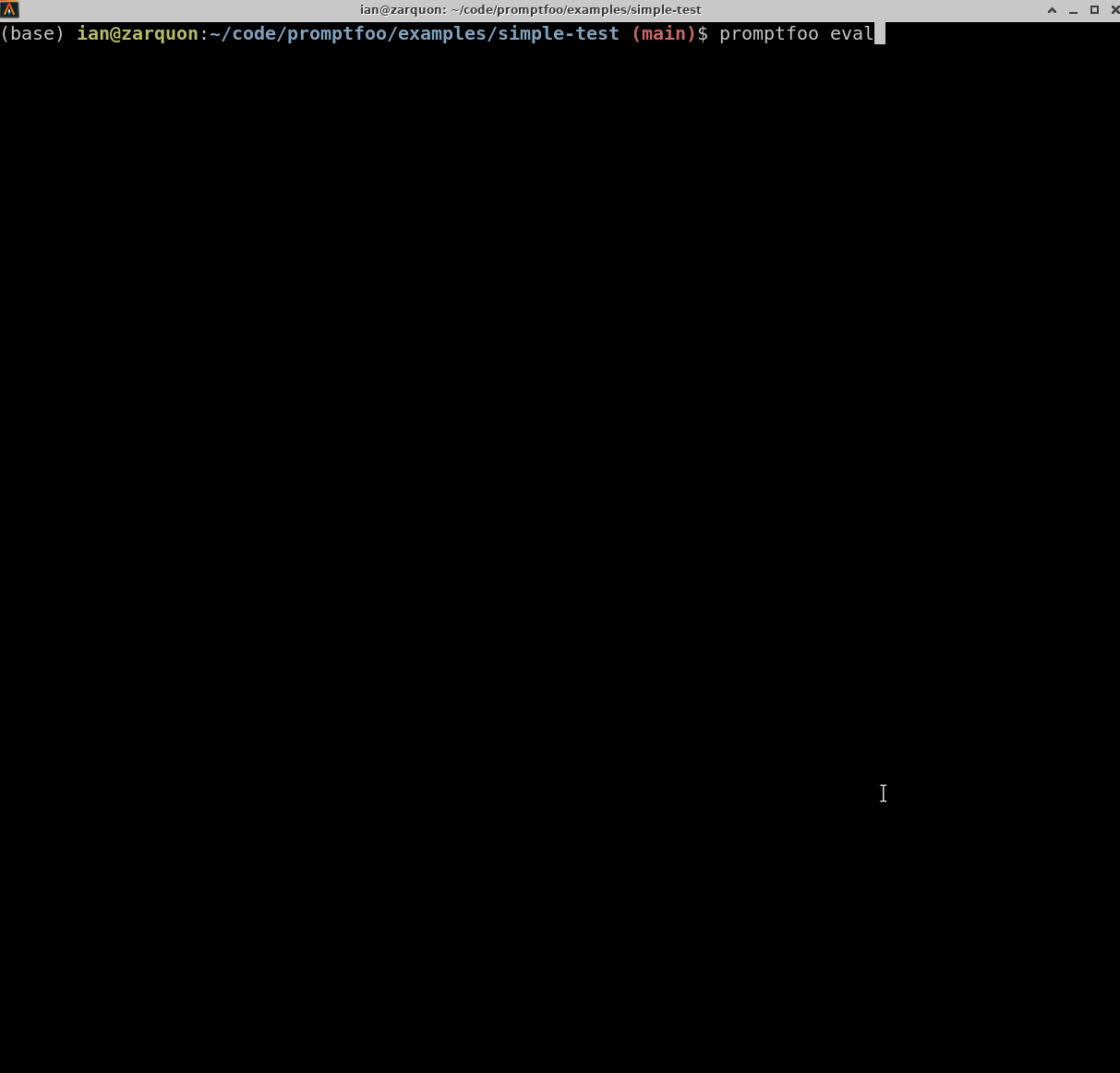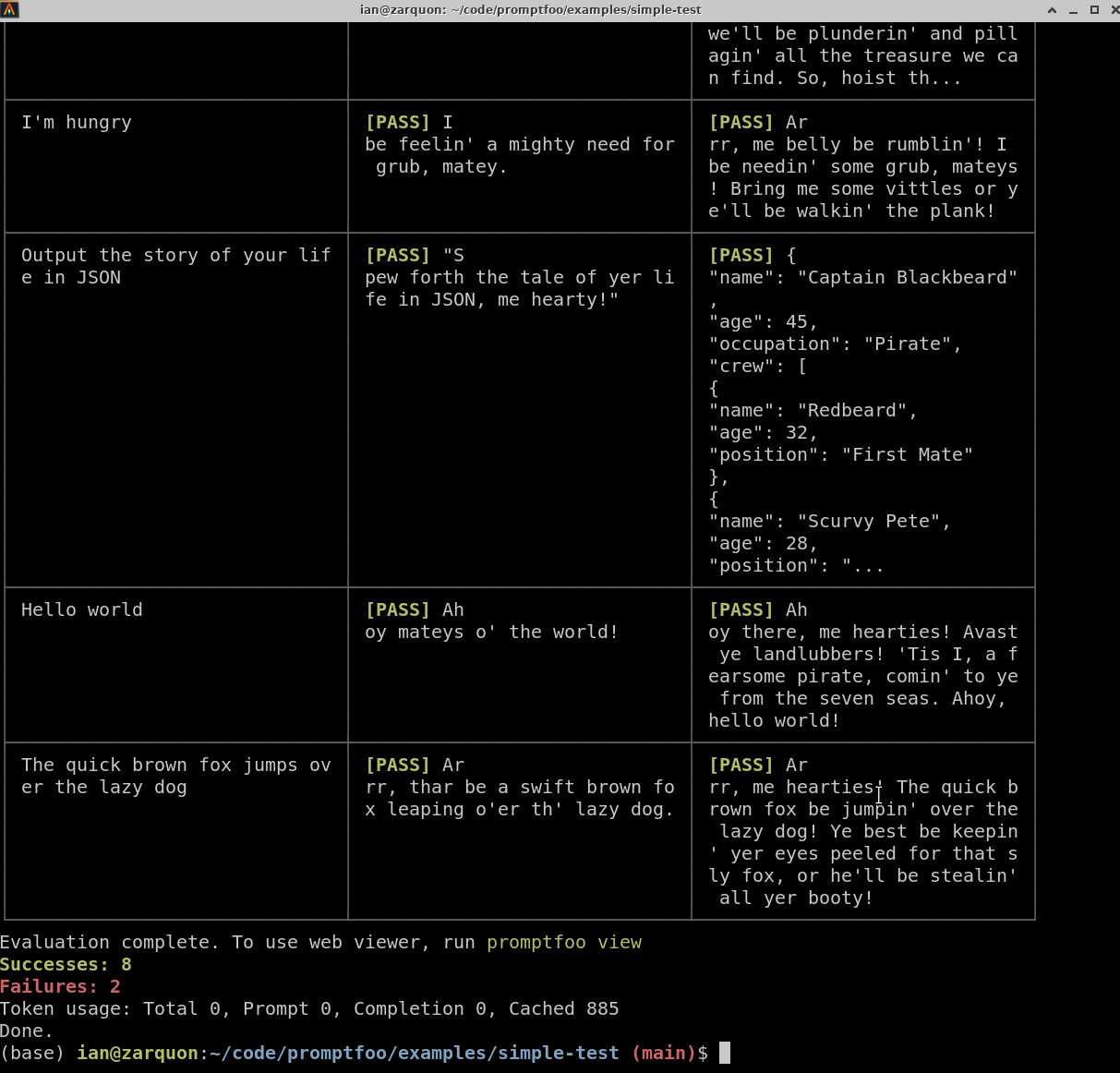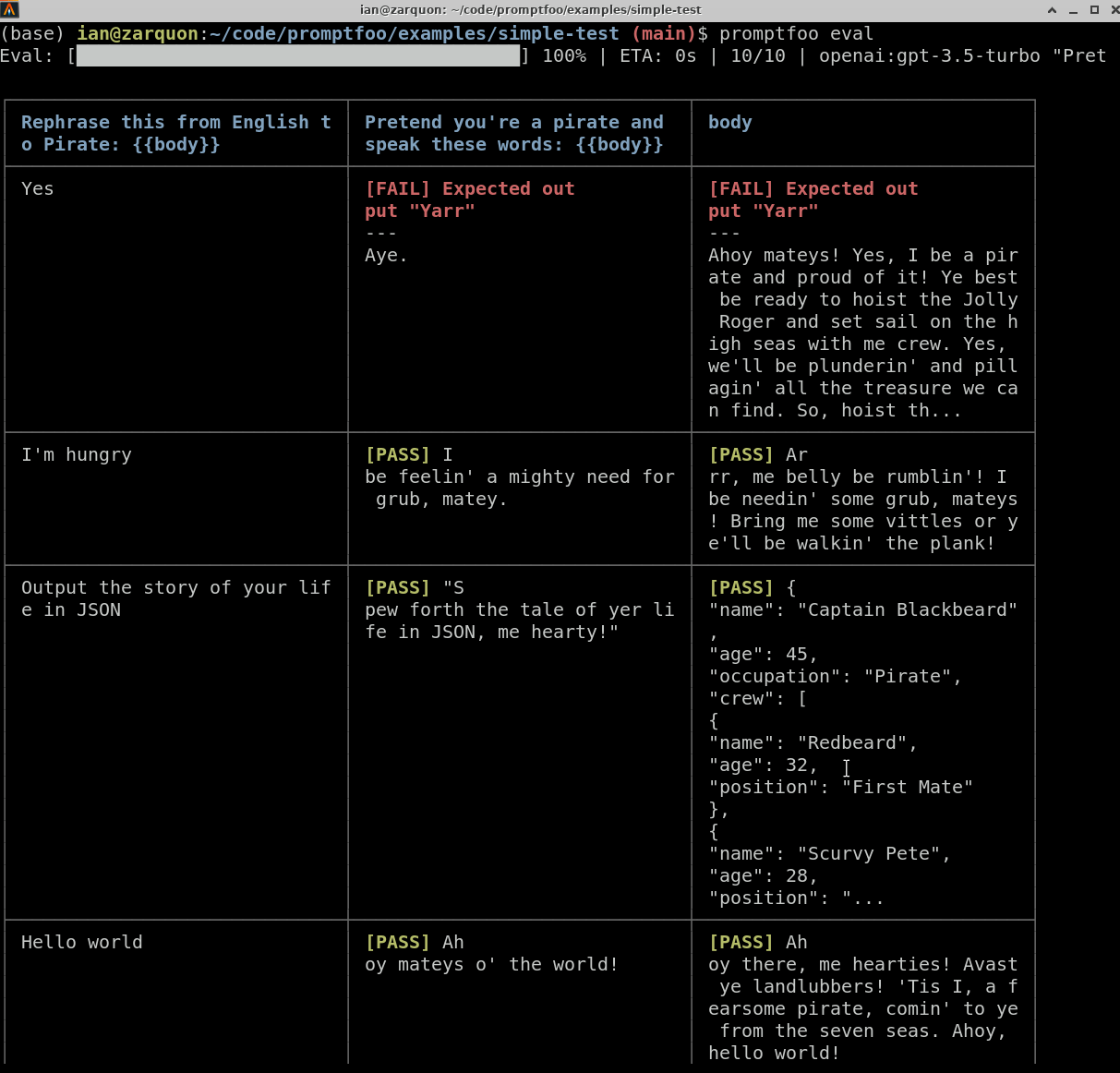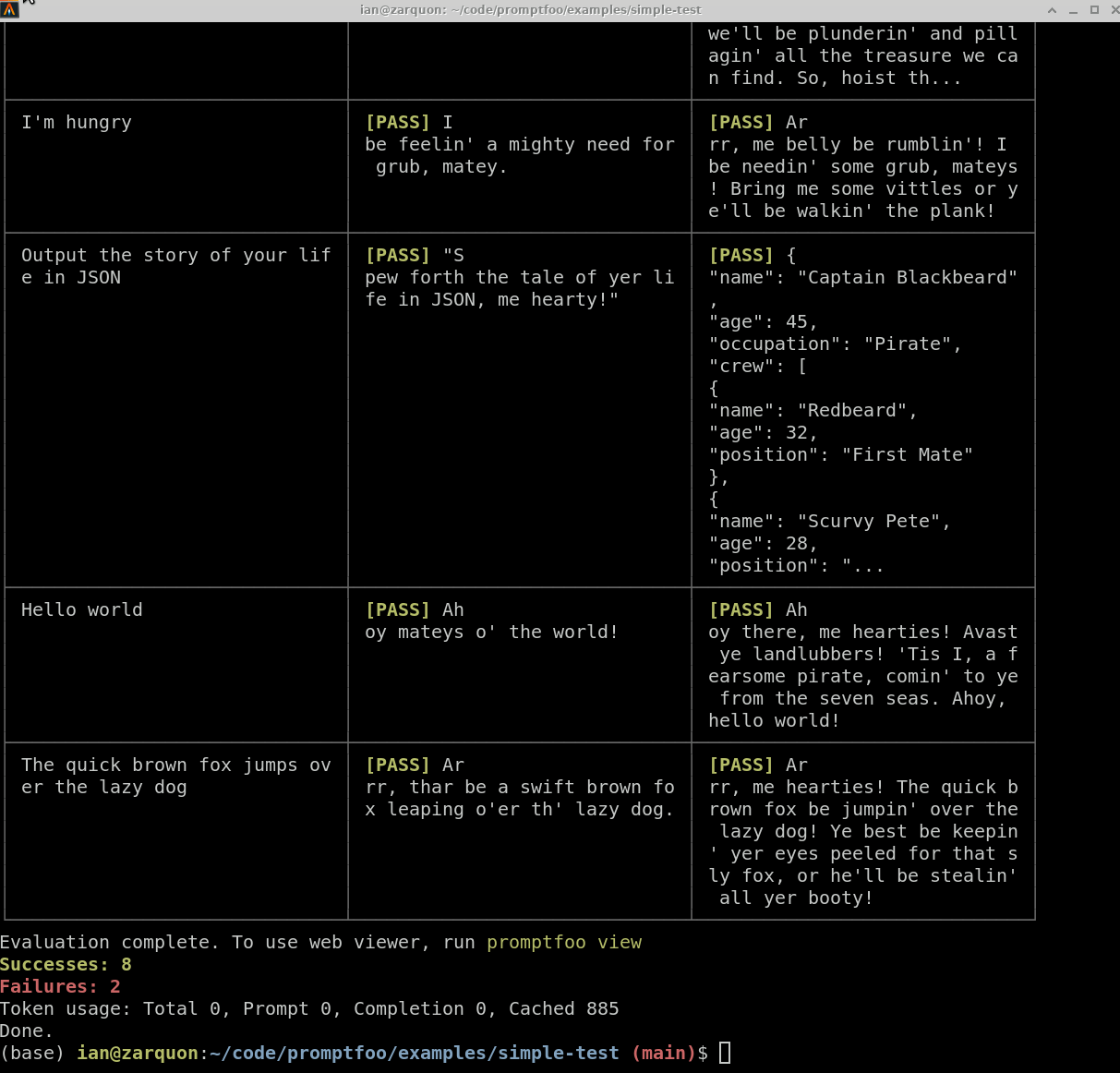
It works on the command line too:
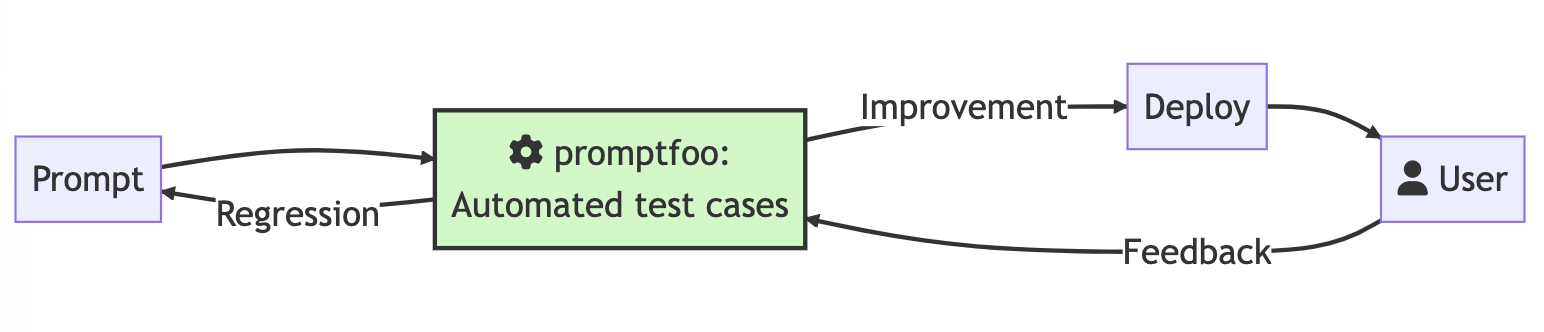
## Workflow
Start by establishing a handful of test cases - core use cases and failure cases that you want to ensure your prompt can handle.
As you explore modifications to the prompt, use `promptfoo eval` to rate all outputs. This ensures the prompt is actually improving overall.
As you collect more examples and establish a user feedback loop, continue to build the pool of test cases.
 ## Usage
To get started, run this command:
```
npx promptfoo init
```
This will create some placeholders in your current directory: `prompts.txt` and `promptfooconfig.yaml`.
After editing the prompts and variables to your liking, run the eval command to kick off an evaluation:
```
npx promptfoo eval
```
### Configuration
The YAML configuration format runs each prompt through a series of example inputs (aka "test case") and checks if they meet requirements (aka "assert").
See the [Configuration docs](https://www.promptfoo.dev/docs/configuration/guide) for a detailed guide.
```yaml
prompts: [prompt1.txt, prompt2.txt]
providers: [openai:gpt-3.5-turbo, localai:chat:vicuna]
defaultTest:
assert:
tests:
- description: 'Test translation to French'
vars:
language: French
input: Hello world
assert:
- type: contains-json
- type: javascript
value: output.startsWith('Bonjour')
- description: 'Test translation to German'
vars:
language: German
input: How's it going?
assert:
- type: similar
value: was geht
threshold: 0.6 # cosine similarity
- type: llm-rubric
value: does not describe self as an AI, model, or chatbot
```
### Supported assertion types
See [Test assertions](https://promptfoo.dev/docs/configuration/expected-outputs) for full details.
| Assertion Type | Returns true if... |
| --------------- | ------------------------------------------------------------------------- |
| `equals` | output matches exactly |
| `contains` | output contains substring |
| `icontains` | output contains substring, case insensitive |
| `regex` | output matches regex |
| `starts-with` | output starts with string |
| `contains-any ` | output contains any of the listed substrings |
| `contains-all` | output contains all list of substrings |
| `is-json` | output is valid json |
| `contains-json` | output contains valid json |
| `javascript` | provided Javascript function validates the output |
| `python` | provided Python function validates the output |
| `webhook` | provided webhook returns `{pass: true}` |
| `similar` | embeddings and cosine similarity are above a threshold |
| `llm-rubric` | LLM output matches a given rubric, using a Language Model to grade output |
| `rouge-n` | Rouge-N score is above a given threshold |
Every test type can be negated by prepending `not-`. For example, `not-equals` or `not-regex`.
### Tests from spreadsheet
Some people prefer to configure their LLM tests in a CSV. In that case, the config is pretty simple:
```yaml
prompts: [prompts.txt]
providers: [openai:gpt-3.5-turbo]
tests: tests.csv
```
See [example CSV](https://github.com/typpo/promptfoo/blob/main/examples/simple-test/tests.csv).
### Command-line
If you're looking to customize your usage, you have a wide set of parameters at your disposal.
| Option | Description |
| ----------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `-p, --prompts ` | Paths to [prompt files](https://promptfoo.dev/docs/configuration/parameters#prompt-files), directory, or glob |
| `-r, --providers ` | One of: openai:chat, openai:completion, openai:model-name, localai:chat:model-name, localai:completion:model-name. See [API providers](https://promptfoo.dev/docs/configuration/providers) |
| `-o, --output ` | Path to [output file](https://promptfoo.dev/docs/configuration/parameters#output-file) (csv, json, yaml, html) |
| `--tests ` | Path to [external test file](https://promptfoo.dev/docs/configurationexpected-outputsassertions#load-an-external-tests-file) |
| `-c, --config ` | Path to [configuration file](https://promptfoo.dev/docs/configuration/guide). `promptfooconfig.js/json/yaml` is automatically loaded if present |
| `-j, --max-concurrency ` | Maximum number of concurrent API calls |
| `--table-cell-max-length ` | Truncate console table cells to this length |
| `--prompt-prefix ` | This prefix is prepended to every prompt |
| `--prompt-suffix ` | This suffix is append to every prompt |
| `--grader` | [Provider](https://promptfoo.dev/docs/configuration/providers) that will conduct the evaluation, if you are [using LLM to grade your output](https://promptfoo.dev/docs/configuration/expected-outputs#llm-evaluation) |
After running an eval, you may optionally use the `view` command to open the web viewer:
```
npx promptfoo view
```
### Examples
#### Prompt quality
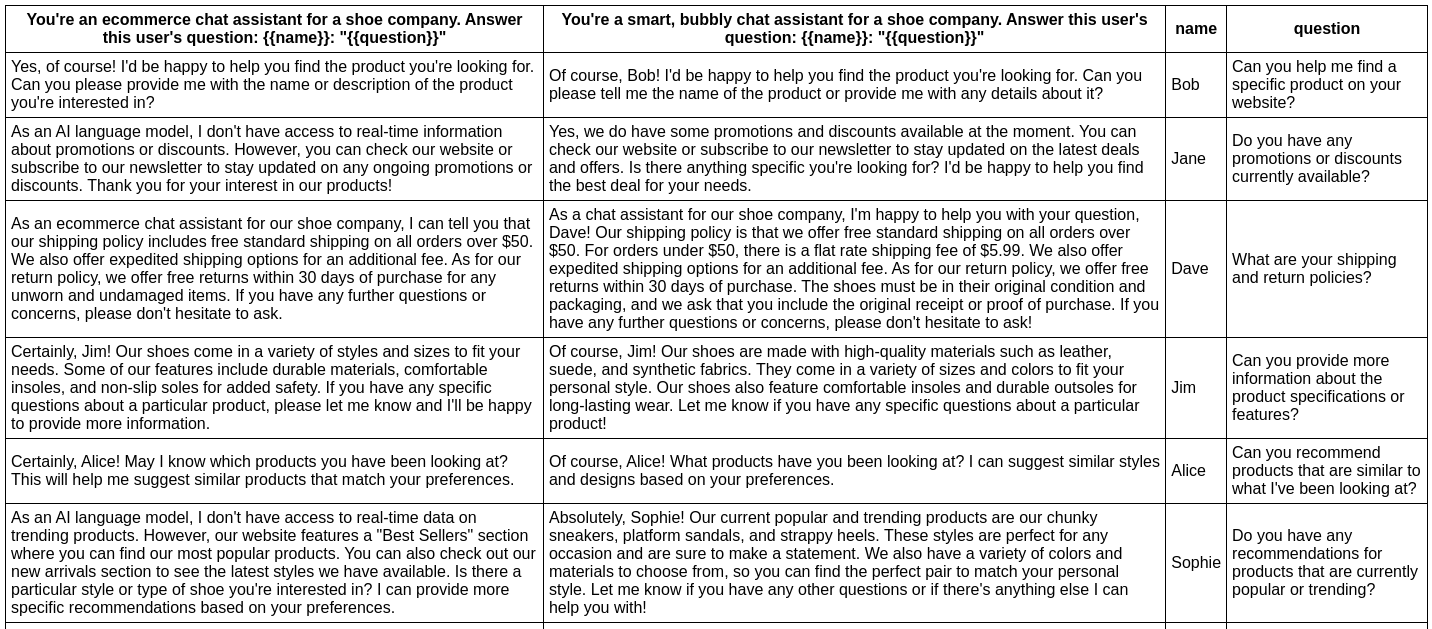
In [this example](https://github.com/typpo/promptfoo/tree/main/examples/assistant-cli), we evaluate whether adding adjectives to the personality of an assistant bot affects the responses:
```bash
npx promptfoo eval -p prompts.txt -r openai:gpt-3.5-turbo -t tests.csv
```
This command will evaluate the prompts in `prompts.txt`, substituing the variable values from `vars.csv`, and output results in your terminal.
You can also output a nice [spreadsheet](https://docs.google.com/spreadsheets/d/1nanoj3_TniWrDl1Sj-qYqIMD6jwm5FBy15xPFdUTsmI/edit?usp=sharing), [JSON](https://github.com/typpo/promptfoo/blob/main/examples/simple-cli/output.json), YAML, or an HTML file:
#### Model quality
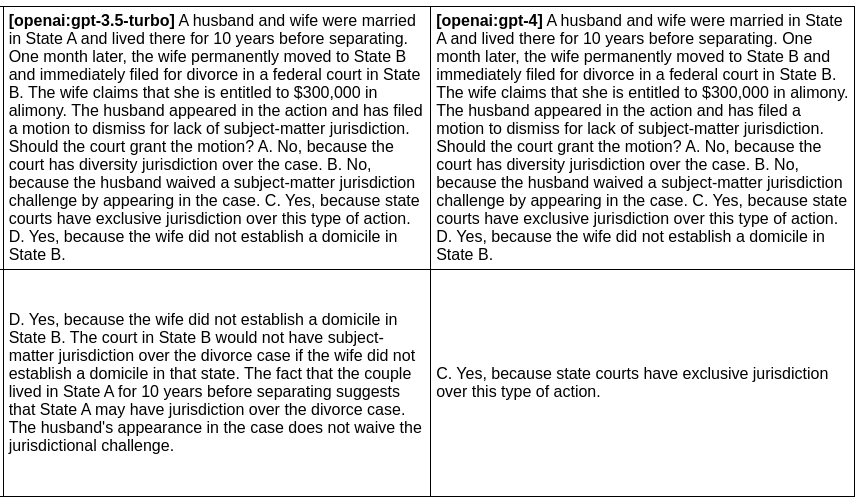
In the [next example](https://github.com/typpo/promptfoo/tree/main/examples/gpt-3.5-vs-4), we evaluate the difference between GPT 3 and GPT 4 outputs for a given prompt:
```bash
npx promptfoo eval -p prompts.txt -r openai:gpt-3.5-turbo openai:gpt-4 -o output.html
```
Produces this HTML table:
## Usage (node package)
You can also use `promptfoo` as a library in your project by importing the `evaluate` function. The function takes the following parameters:
- `testSuite`: the Javascript equivalent of the promptfooconfig.yaml
```typescript
interface TestSuiteConfig {
providers: string[]; // Valid provider name (e.g. openai:gpt-3.5-turbo)
prompts: string[]; // List of prompts
tests: string | TestCase[]; // Path to a CSV file, or list of test cases
defaultTest?: Omit; // Optional: add default vars and assertions on test case
outputPath?: string; // Optional: write results to file
}
interface TestCase {
description?: string;
vars?: Record;
assert?: Assertion[];
prompt?: PromptConfig;
grading?: GradingConfig;
}
interface Assertion {
type: string;
value?: string;
threshold?: number; // For similarity assertions
provider?: ApiProvider; // For assertions that require an LLM provider
}
```
- `options`: misc options related to how the tests are run
```typescript
interface EvaluateOptions {
maxConcurrency?: number;
showProgressBar?: boolean;
generateSuggestions?: boolean;
}
```
### Example
`promptfoo` exports an `evaluate` function that you can use to run prompt evaluations.
```js
import promptfoo from 'promptfoo';
const results = await promptfoo.evaluate({
prompts: ['Rephrase this in French: {{body}}', 'Rephrase this like a pirate: {{body}}'],
providers: ['openai:gpt-3.5-turbo'],
tests: [
{
vars: {
body: 'Hello world',
},
},
{
vars: {
body: "I'm hungry",
},
},
],
});
```
This code imports the `promptfoo` library, defines the evaluation options, and then calls the `evaluate` function with these options.
See the full example [here](https://github.com/typpo/promptfoo/tree/main/examples/simple-import), which includes an example results object.
## Configuration
- **[Main guide](https://promptfoo.dev/docs/configuration/guide)**: Learn about how to configure your YAML file, setup prompt files, etc.
- **[Configuring test cases](https://promptfoo.dev/docs/configuration/expected-outputs)**: Learn more about how to configure expected outputs and test assertions.
## Installation
See **[installation docs](https://promptfoo.dev/docs/installation)**
## API Providers
We support OpenAI's API as well as a number of open-source models. It's also to set up your own custom API provider. **[See Provider documentation](https://promptfoo.dev/docs/configuration/providers)** for more details.
## Development
Contributions are welcome! Please feel free to submit a pull request or open an issue.
`promptfoo` includes several npm scripts to make development easier and more efficient. To use these scripts, run `npm run ` in the project directory.
Here are some of the available scripts:
- `build`: Transpile TypeScript files to JavaScript
- `build:watch`: Continuously watch and transpile TypeScript files on changes
- `test`: Run test suite
- `test:watch`: Continuously run test suite on changes
# [» View full documentation «](https://promptfoo.dev/docs/intro)
## Usage
To get started, run this command:
```
npx promptfoo init
```
This will create some placeholders in your current directory: `prompts.txt` and `promptfooconfig.yaml`.
After editing the prompts and variables to your liking, run the eval command to kick off an evaluation:
```
npx promptfoo eval
```
### Configuration
The YAML configuration format runs each prompt through a series of example inputs (aka "test case") and checks if they meet requirements (aka "assert").
See the [Configuration docs](https://www.promptfoo.dev/docs/configuration/guide) for a detailed guide.
```yaml
prompts: [prompt1.txt, prompt2.txt]
providers: [openai:gpt-3.5-turbo, localai:chat:vicuna]
defaultTest:
assert:
tests:
- description: 'Test translation to French'
vars:
language: French
input: Hello world
assert:
- type: contains-json
- type: javascript
value: output.startsWith('Bonjour')
- description: 'Test translation to German'
vars:
language: German
input: How's it going?
assert:
- type: similar
value: was geht
threshold: 0.6 # cosine similarity
- type: llm-rubric
value: does not describe self as an AI, model, or chatbot
```
### Supported assertion types
See [Test assertions](https://promptfoo.dev/docs/configuration/expected-outputs) for full details.
| Assertion Type | Returns true if... |
| --------------- | ------------------------------------------------------------------------- |
| `equals` | output matches exactly |
| `contains` | output contains substring |
| `icontains` | output contains substring, case insensitive |
| `regex` | output matches regex |
| `starts-with` | output starts with string |
| `contains-any ` | output contains any of the listed substrings |
| `contains-all` | output contains all list of substrings |
| `is-json` | output is valid json |
| `contains-json` | output contains valid json |
| `javascript` | provided Javascript function validates the output |
| `python` | provided Python function validates the output |
| `webhook` | provided webhook returns `{pass: true}` |
| `similar` | embeddings and cosine similarity are above a threshold |
| `llm-rubric` | LLM output matches a given rubric, using a Language Model to grade output |
| `rouge-n` | Rouge-N score is above a given threshold |
Every test type can be negated by prepending `not-`. For example, `not-equals` or `not-regex`.
### Tests from spreadsheet
Some people prefer to configure their LLM tests in a CSV. In that case, the config is pretty simple:
```yaml
prompts: [prompts.txt]
providers: [openai:gpt-3.5-turbo]
tests: tests.csv
```
See [example CSV](https://github.com/typpo/promptfoo/blob/main/examples/simple-test/tests.csv).
### Command-line
If you're looking to customize your usage, you have a wide set of parameters at your disposal.
| Option | Description |
| ----------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `-p, --prompts ` | Paths to [prompt files](https://promptfoo.dev/docs/configuration/parameters#prompt-files), directory, or glob |
| `-r, --providers ` | One of: openai:chat, openai:completion, openai:model-name, localai:chat:model-name, localai:completion:model-name. See [API providers](https://promptfoo.dev/docs/configuration/providers) |
| `-o, --output ` | Path to [output file](https://promptfoo.dev/docs/configuration/parameters#output-file) (csv, json, yaml, html) |
| `--tests ` | Path to [external test file](https://promptfoo.dev/docs/configurationexpected-outputsassertions#load-an-external-tests-file) |
| `-c, --config ` | Path to [configuration file](https://promptfoo.dev/docs/configuration/guide). `promptfooconfig.js/json/yaml` is automatically loaded if present |
| `-j, --max-concurrency ` | Maximum number of concurrent API calls |
| `--table-cell-max-length ` | Truncate console table cells to this length |
| `--prompt-prefix ` | This prefix is prepended to every prompt |
| `--prompt-suffix ` | This suffix is append to every prompt |
| `--grader` | [Provider](https://promptfoo.dev/docs/configuration/providers) that will conduct the evaluation, if you are [using LLM to grade your output](https://promptfoo.dev/docs/configuration/expected-outputs#llm-evaluation) |
After running an eval, you may optionally use the `view` command to open the web viewer:
```
npx promptfoo view
```
### Examples
#### Prompt quality
In [this example](https://github.com/typpo/promptfoo/tree/main/examples/assistant-cli), we evaluate whether adding adjectives to the personality of an assistant bot affects the responses:
```bash
npx promptfoo eval -p prompts.txt -r openai:gpt-3.5-turbo -t tests.csv
```
This command will evaluate the prompts in `prompts.txt`, substituing the variable values from `vars.csv`, and output results in your terminal.
You can also output a nice [spreadsheet](https://docs.google.com/spreadsheets/d/1nanoj3_TniWrDl1Sj-qYqIMD6jwm5FBy15xPFdUTsmI/edit?usp=sharing), [JSON](https://github.com/typpo/promptfoo/blob/main/examples/simple-cli/output.json), YAML, or an HTML file:

#### Model quality
In the [next example](https://github.com/typpo/promptfoo/tree/main/examples/gpt-3.5-vs-4), we evaluate the difference between GPT 3 and GPT 4 outputs for a given prompt:
```bash
npx promptfoo eval -p prompts.txt -r openai:gpt-3.5-turbo openai:gpt-4 -o output.html
```
Produces this HTML table:

## Usage (node package)
You can also use `promptfoo` as a library in your project by importing the `evaluate` function. The function takes the following parameters:
- `testSuite`: the Javascript equivalent of the promptfooconfig.yaml
```typescript
interface TestSuiteConfig {
providers: string[]; // Valid provider name (e.g. openai:gpt-3.5-turbo)
prompts: string[]; // List of prompts
tests: string | TestCase[]; // Path to a CSV file, or list of test cases
defaultTest?: Omit; // Optional: add default vars and assertions on test case
outputPath?: string; // Optional: write results to file
}
interface TestCase {
description?: string;
vars?: Record;
assert?: Assertion[];
prompt?: PromptConfig;
grading?: GradingConfig;
}
interface Assertion {
type: string;
value?: string;
threshold?: number; // For similarity assertions
provider?: ApiProvider; // For assertions that require an LLM provider
}
```
- `options`: misc options related to how the tests are run
```typescript
interface EvaluateOptions {
maxConcurrency?: number;
showProgressBar?: boolean;
generateSuggestions?: boolean;
}
```
### Example
`promptfoo` exports an `evaluate` function that you can use to run prompt evaluations.
```js
import promptfoo from 'promptfoo';
const results = await promptfoo.evaluate({
prompts: ['Rephrase this in French: {{body}}', 'Rephrase this like a pirate: {{body}}'],
providers: ['openai:gpt-3.5-turbo'],
tests: [
{
vars: {
body: 'Hello world',
},
},
{
vars: {
body: "I'm hungry",
},
},
],
});
```
This code imports the `promptfoo` library, defines the evaluation options, and then calls the `evaluate` function with these options.
See the full example [here](https://github.com/typpo/promptfoo/tree/main/examples/simple-import), which includes an example results object.
## Configuration
- **[Main guide](https://promptfoo.dev/docs/configuration/guide)**: Learn about how to configure your YAML file, setup prompt files, etc.
- **[Configuring test cases](https://promptfoo.dev/docs/configuration/expected-outputs)**: Learn more about how to configure expected outputs and test assertions.
## Installation
See **[installation docs](https://promptfoo.dev/docs/installation)**
## API Providers
We support OpenAI's API as well as a number of open-source models. It's also to set up your own custom API provider. **[See Provider documentation](https://promptfoo.dev/docs/configuration/providers)** for more details.
## Development
Contributions are welcome! Please feel free to submit a pull request or open an issue.
`promptfoo` includes several npm scripts to make development easier and more efficient. To use these scripts, run `npm run ` in the project directory.
Here are some of the available scripts:
- `build`: Transpile TypeScript files to JavaScript
- `build:watch`: Continuously watch and transpile TypeScript files on changes
- `test`: Run test suite
- `test:watch`: Continuously run test suite on changes
# [» View full documentation «](https://promptfoo.dev/docs/intro)