promptfoo
promptfoo is a library and command-line tool that helps you evaluate LLM prompt & model quality with a systematic approach to comparing model outputs.
With promptfoo, you can:
- Test multiple prompts against predefined test cases
- Evaluate quality and catch regressions by comparing LLM outputs side-by-side
- Speed up evaluations by running tests concurrently
- Use as a command line tool, or integrate into your workflow as a library
- Use OpenAI API models (built-in support), or integrate custom API providers for any LLM API
Usage (command line)
To evaluate prompts using promptfoo, use the following command:
npx promptfoo eval -p <prompt_paths...> -o <output_path> -r <provider> [-v <vars_path>] [-j <max_concurrency] [-c <config_path>]
<prompt_paths...>: Paths to prompt file(s)<output_path>: Path to output CSV, JSON, YAML, or HTML file. Defaults to terminal output<provider>: One or more of:openai:<model_name>, or filesystem path to custom API caller module<vars_path>(optional): Path to CSV, JSON, or YAML file with prompt variables<max_concurrency>(optional): Number of simultaneous API requests. Defaults to 3<config_path>(optional): Path to configuration file
Examples
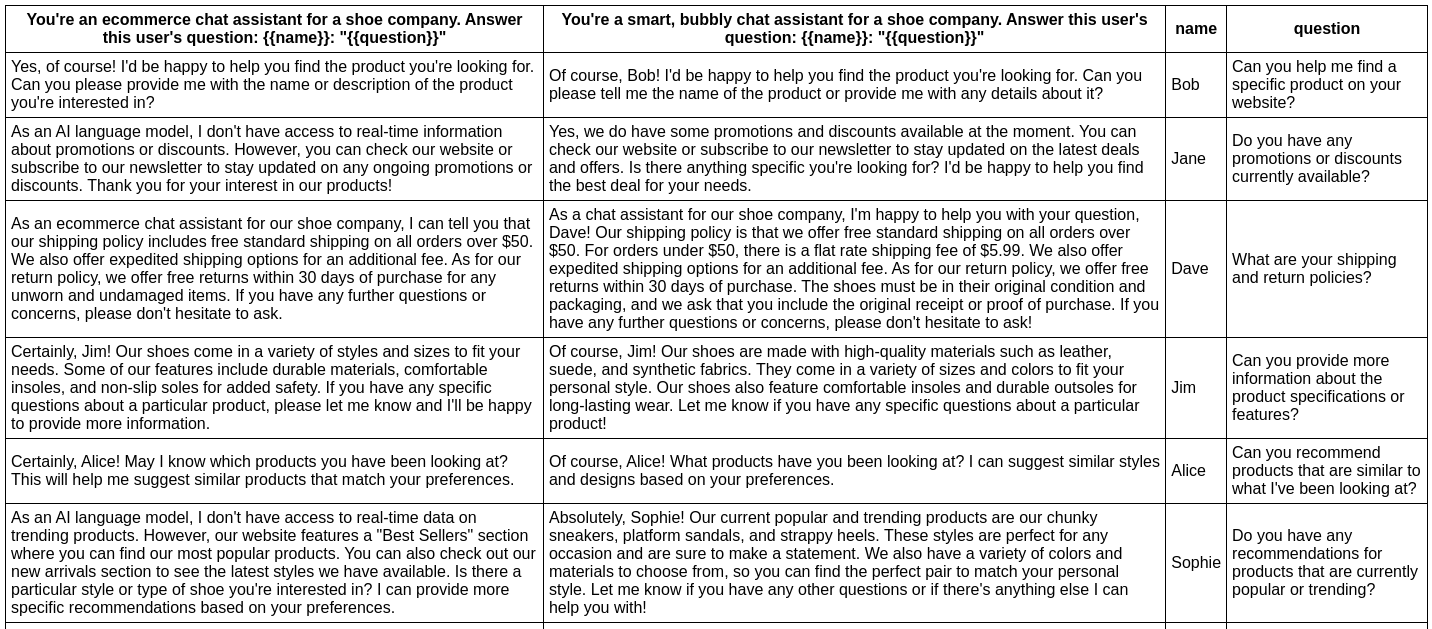
Prompt quality
In this example, we evaluate whether adding adjectives to the personality of an assistant bot affects the responses:
npx promptfoo eval -p prompts.txt -v vars.csv -r openai:gpt-3.5-turbo

This command will evaluate the prompts in prompts.txt, substituing the variable values from vars.csv, and output results in your terminal.
Have a look at the setup and full output here.
You can run the command without an -o option to output in your terminal (example), or use -o to specify an HTML (example), CSV (example), JSON (example), or YAML output.
{kind=link}
{kind=link}
Model quality
In this example, we evaluate the difference between GPT 3 and GPT 4 outputs for a given prompt:
npx promptfoo eval -p prompts.txt -r openai:gpt-3.5-turbo openai:gpt-4 -o output.html
Produces this HTML table:
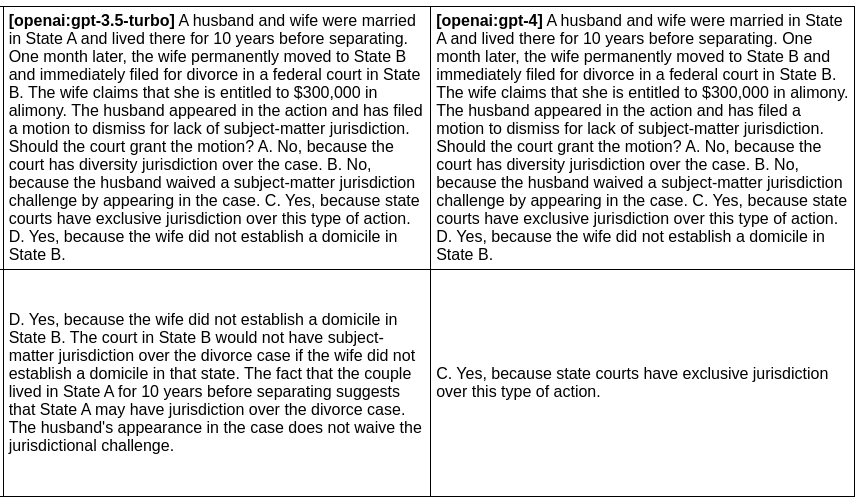
Full setup and output here.
Usage (as a library)
You can also use promptfoo as a library in your project by importing the evaluate function. The function takes the following parameters:
-
providers: a list of provider strings orApiProviderobjects, or just a single string orApiProvider. -
options: the prompts and variables you want to test:{ prompts: string[]; vars?: Record<string, string>; }
Example
promptfoo exports an evaluate function that you can use to run prompt evaluations.
import promptfoo from 'promptfoo';
const options = {
prompts: ['Rephrase this in French: {{body}}', 'Rephrase this like a pirate: {{body}}'],
vars: [{ body: 'Hello world' }, { body: "I'm hungry" }],
};
(async () => {
const summary = await promptfoo.evaluate('openai:gpt-3.5-turbo', options);
console.log(summary);
})();
This code imports the promptfoo library, defines the evaluation options, and then calls the evaluate function with these options. The results are logged to the console:
{
"results": [
{
"prompt": {
"raw": "Rephrase this in French: Hello world",
"display": "Rephrase this in French: {{body}}"
},
"vars": {
"body": "Hello world"
},
"response": {
"output": "Bonjour le monde",
"tokenUsage": {
"total": 19,
"prompt": 16,
"completion": 3
}
}
},
// ...
],
"stats": {
"successes": 4,
"failures": 0,
"tokenUsage": {
"total": 120,
"prompt": 72,
"completion": 48
}
},
"table": [
// ...
]
}
Configuration
Prompt Files
Prompt files are plain text files that contain the prompts you want to test. If you have only one file, you can include multiple prompts in the file, separated by the delimiter ---. If you have multiple files, each prompt should be in a separate file.
You can use Nunjucks templating syntax to include variables in your prompts, which will be replaced with actual values from the vars CSV file during evaluation.
Example of a single prompt file with multiple prompts (prompts.txt):
Translate the following text to French: "{{text}}"
---
Translate the following text to German: "{{text}}"
Example of multiple prompt files:
-
prompt1.txt:Translate the following text to French: "{{text}}" -
prompt2.txt:Translate the following text to German: "{{text}}"
Vars File
The Vars file is a CSV, JSON, or YAML file that contains the values for the variables used in the prompts. The first row of the CSV file should contain the variable names, and each subsequent row should contain the corresponding values for each test case.
Vars are substituted by Nunjucks templating syntax into prompts.
Example of a vars file (vars.csv):
text
"Hello, world!"
"Goodbye, everyone!"
Example of a vars file (vars.json):
[{ "text": "Hello, world!" }, { "text": "Goodbye, everyone!" }]
Expected Value
You can specify an expected value for each test case to evaluate the success or failure of the model's output. To do this, add a special field called __expected in the vars file. The __expected field supports three types of value comparisons:
-
If the expected value starts with
eval:, it will evaluate the contents as the body of a JavaScript function defined like:function(output) { <eval> }. The function should return a boolean value, wheretrueindicates success andfalseindicates failure. -
If the expected value starts with
grade:, it will call thegradeOutput(prompt, output)function. You should assume this function exists and returns a boolean value, wheretrueindicates success andfalseindicates failure. -
Otherwise, it attempts an exact string match comparison between the expected value and the model's output.
Example of a vars file with the __expected field (vars.csv):
text,__expected
"Hello, world!","Bonjour le monde"
"Goodbye, everyone!","eval:return output.includes('Au revoir');"
Example of a vars file with the __expected field (vars.json):
[
{ "text": "Hello, world!", "__expected": "Bonjour le monde" },
{ "text": "Goodbye, everyone!", "__expected": "eval:output.includes('Au revoir');" }
]
When the __expected field is provided, the success and failure statistics in the evaluation summary will be based on whether the expected criteria are met.
For more advanced test cases, we recommend using a testing framework like Jest or Mocha and using promptfoo as a library.
Output File
The results of the evaluation are written to this file. Each record in the output file corresponds to a test case and includes the original prompt, the output generated by the LLM, and the values of the variables used in the test case.
For example outputs, see the examples/ directory.
Configuration File
You can specify any option in a configuration file (e.g., .promptfoorc, promptfoo.config.json). This can help you avoid repetitive command-line options and simplify the CLI invocation.
Example of a configuration file (promptfoo.config.json):
{
"provider": "openai:chat",
"vars": "/path/to/vars.csv"
}
Installation
- Clone the repository:
git clone https://github.com/typpo/promptfoo.git
- Install the dependencies:
npm install
- Link the CLI tool:
npm link
Example
promptfoo eval -p prompt1.txt prompt2.txt -o results.csv -r openai:chat -v vars.csv
API Providers
promptfoo supports OpenAI API models out of the box. To use a custom API provider, create a custom module that implements the ApiProvider interface and pass the path to the module as the provider option.
OpenAI API
To use the OpenAI API, set the OPENAI_API_KEY environment variable or pass the API key as an argument to the constructor.
Example:
export OPENAI_API_KEY=your_api_key_here
Other OpenAI-related environment variables are supported:
OPENAI_TEMPERATURE- temperature model parameter, defaults to 0OPENAI_MAX_TOKENS- max_tokens model parameter, defaults to 1024
The OpenAI provider supports the following model formats:
openai:chat- defaults to gpt-3.5-turboopenai:completion- defaults totext-davinci-003openai:<model name>- uses a specific model name (mapped automatically to chat or completion endpoint)openai:chat:<model name>- uses any model name against the chat endpointopenai:completion:<model name>- uses any model name against the completion endpoint
The openai:<endpoint>:<model> construction is useful if OpenAI releases a new model, or if you have a custom model. For example, if OpenAI releases gpt-5 chat completion, you could begin using it immediately with openai:chat:gpt-5.
Custom API Provider
To create a custom API provider, implement the ApiProvider interface in a separate module. Here is the interface:
export interface ApiProvider {
id: () => string;
callApi: (prompt: string) => Promise<ProviderResult>;
}
Below is an example of a custom API provider that returns a predefined output and token usage:
// customApiProvider.js
class CustomApiProvider {
id() {
return 'my-custom-api';
}
async callApi(prompt) {
// Add your custom API logic here
return {
// Required
output: 'Model output',
// Optional
tokenUsage: {
total: 10,
prompt: 5,
completion: 5,
},
};
}
}
module.exports.default = CustomApiProvider;
To use the custom API provider with promptfoo, pass the path to the module as the provider option in the CLI invocation:
promptfoo eval -p prompt1.txt prompt2.txt -o results.csv -v vars.csv -r ./customApiProvider.js
This command will evaluate the prompts using the custom API provider and save the results to the specified CSV file.
Development
Contributions are welcome! Please feel free to submit a pull request or open an issue.
promptfoo includes several npm scripts to make development easier and more efficient. To use these scripts, run npm run <script_name> in the project directory.
Here are some of the available scripts:
build: Transpile TypeScript files to JavaScriptwatch: Continuously watch and transpile TypeScript files on changestest: Run test suitetest:watch: Continuously run test suite on changes