# 🚀 RAG-Anything: All-in-One RAG System

---
## 🎉 News
- [X] [2025.08.12]🎯📢 🔍 RAG-Anything now features **VLM-Enhanced Query** mode! When documents include images, the system seamlessly integrates them into VLM for advanced multimodal analysis, combining visual and textual context for deeper insights.
- [X] [2025.07.05]🎯📢 RAG-Anything now features a [context configuration module](docs/context_aware_processing.md), enabling intelligent integration of relevant contextual information to enhance multimodal content processing.
- [X] [2025.07.04]🎯📢 🚀 RAG-Anything now supports multimodal query capabilities, enabling enhanced RAG with seamless processing of text, images, tables, and equations.
- [X] [2025.07.03]🎯📢 🎉 RAG-Anything has reached 1k🌟 stars on GitHub! Thank you for your incredible support and valuable contributions to the project.
---
## 🌟 System Overview
*Next-Generation Multimodal Intelligence*
Modern documents increasingly contain diverse multimodal content—text, images, tables, equations, charts, and multimedia—that traditional text-focused RAG systems cannot effectively process. **RAG-Anything** addresses this challenge as a comprehensive **All-in-One Multimodal Document Processing RAG system** built on [LightRAG](https://github.com/HKUDS/LightRAG).
As a unified solution, RAG-Anything **eliminates the need for multiple specialized tools**. It provides **seamless processing and querying across all content modalities** within a single integrated framework. Unlike conventional RAG approaches that struggle with non-textual elements, our all-in-one system delivers **comprehensive multimodal retrieval capabilities**.
Users can query documents containing **interleaved text**, **visual diagrams**, **structured tables**, and **mathematical formulations** through **one cohesive interface**. This consolidated approach makes RAG-Anything particularly valuable for academic research, technical documentation, financial reports, and enterprise knowledge management where rich, mixed-content documents demand a **unified processing framework**.
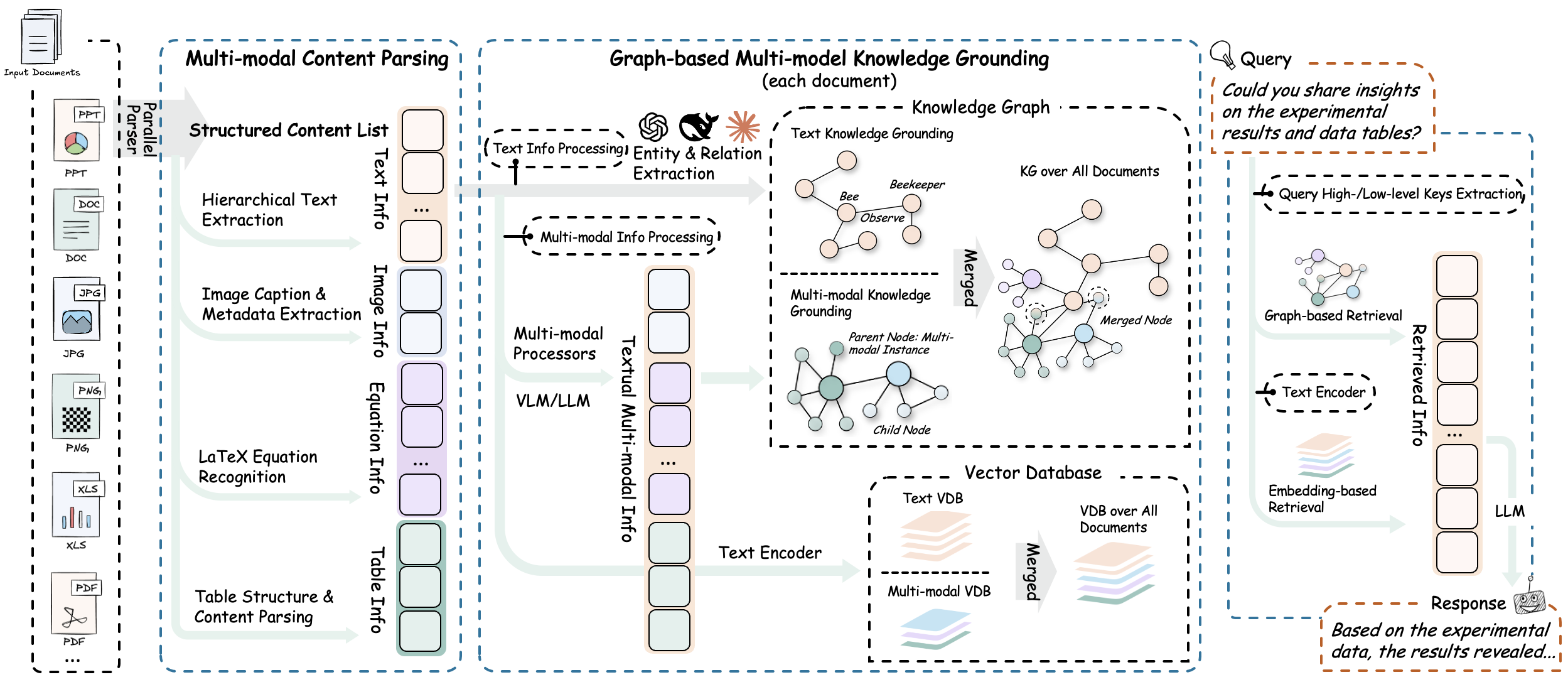
- **🔄 End-to-End Multimodal Pipeline** - Complete workflow from document ingestion and parsing to intelligent multimodal query answering
- **📄 Universal Document Support** - Seamless processing of PDFs, Office documents, images, and diverse file formats
- **🧠 Specialized Content Analysis** - Dedicated processors for images, tables, mathematical equations, and heterogeneous content types
- **🔗 Multimodal Knowledge Graph** - Automatic entity extraction and cross-modal relationship discovery for enhanced understanding
- **⚡ Adaptive Processing Modes** - Flexible MinerU-based parsing or direct multimodal content injection workflows
- **📋 Direct Content List Insertion** - Bypass document parsing by directly inserting pre-parsed content lists from external sources
- **🎯 Hybrid Intelligent Retrieval** - Advanced search capabilities spanning textual and multimodal content with contextual understanding
---
## 🏗️ Algorithm & Architecture
### Core Algorithm
**RAG-Anything** implements an effective **multi-stage multimodal pipeline** that fundamentally extends traditional RAG architectures to seamlessly handle diverse content modalities through intelligent orchestration and cross-modal understanding.
### 1. Document Parsing Stage
The system provides high-fidelity document extraction through adaptive content decomposition. It intelligently segments heterogeneous elements while preserving contextual relationships. Universal format compatibility is achieved via specialized optimized parsers.
**Key Components:**
- **⚙️ MinerU Integration**: Leverages [MinerU](https://github.com/opendatalab/MinerU) for high-fidelity document structure extraction and semantic preservation across complex layouts.
- **🧩 Adaptive Content Decomposition**: Automatically segments documents into coherent text blocks, visual elements, structured tables, mathematical equations, and specialized content types while preserving contextual relationships.
- **📁 Universal Format Support**: Provides comprehensive handling of PDFs, Office documents (DOC/DOCX/PPT/PPTX/XLS/XLSX), images, and emerging formats through specialized parsers with format-specific optimization.
### 2. Multi-Modal Content Understanding & Processing
The system automatically categorizes and routes content through optimized channels. It uses concurrent pipelines for parallel text and multimodal processing. Document hierarchy and relationships are preserved during transformation.
**Key Components:**
- **🎯 Autonomous Content Categorization and Routing**: Automatically identify, categorize, and route different content types through optimized execution channels.
- **⚡ Concurrent Multi-Pipeline Architecture**: Implements concurrent execution of textual and multimodal content through dedicated processing pipelines. This approach maximizes throughput efficiency while preserving content integrity.
- **🏗️ Document Hierarchy Extraction**: Extracts and preserves original document hierarchy and inter-element relationships during content transformation.
### 3. Multimodal Analysis Engine
The system deploys modality-aware processing units for heterogeneous data modalities:
**Specialized Analyzers:**
- **🔍 Visual Content Analyzer**:
- Integrate vision model for image analysis.
- Generates context-aware descriptive captions based on visual semantics.
- Extracts spatial relationships and hierarchical structures between visual elements.
- **📊 Structured Data Interpreter**:
- Performs systematic interpretation of tabular and structured data formats.
- Implements statistical pattern recognition algorithms for data trend analysis.
- Identifies semantic relationships and dependencies across multiple tabular datasets.
- **📐 Mathematical Expression Parser**:
- Parses complex mathematical expressions and formulas with high accuracy.
- Provides native LaTeX format support for seamless integration with academic workflows.
- Establishes conceptual mappings between mathematical equations and domain-specific knowledge bases.
- **🔧 Extensible Modality Handler**:
- Provides configurable processing framework for custom and emerging content types.
- Enables dynamic integration of new modality processors through plugin architecture.
- Supports runtime configuration of processing pipelines for specialized use cases.
### 4. Multimodal Knowledge Graph Index
The multi-modal knowledge graph construction module transforms document content into structured semantic representations. It extracts multimodal entities, establishes cross-modal relationships, and preserves hierarchical organization. The system applies weighted relevance scoring for optimized knowledge retrieval.
**Core Functions:**
- **🔍 Multi-Modal Entity Extraction**: Transforms significant multimodal elements into structured knowledge graph entities. The process includes semantic annotations and metadata preservation.
- **🔗 Cross-Modal Relationship Mapping**: Establishes semantic connections and dependencies between textual entities and multimodal components. This is achieved through automated relationship inference algorithms.
- **🏗️ Hierarchical Structure Preservation**: Maintains original document organization through "belongs_to" relationship chains. These chains preserve logical content hierarchy and sectional dependencies.
- **⚖️ Weighted Relationship Scoring**: Assigns quantitative relevance scores to relationship types. Scoring is based on semantic proximity and contextual significance within the document structure.
### 5. Modality-Aware Retrieval
The hybrid retrieval system combines vector similarity search with graph traversal algorithms for comprehensive content retrieval. It implements modality-aware ranking mechanisms and maintains relational coherence between retrieved elements to ensure contextually integrated information delivery.
**Retrieval Mechanisms:**
- **🔀 Vector-Graph Fusion**: Integrates vector similarity search with graph traversal algorithms. This approach leverages both semantic embeddings and structural relationships for comprehensive content retrieval.
- **📊 Modality-Aware Ranking**: Implements adaptive scoring mechanisms that weight retrieval results based on content type relevance. The system adjusts rankings according to query-specific modality preferences.
- **🔗 Relational Coherence Maintenance**: Maintains semantic and structural relationships between retrieved elements. This ensures coherent information delivery and contextual integrity.
---
## 🚀 Quick Start
*Initialize Your AI Journey*
### Installation
#### Option 1: Install from PyPI (Recommended)
```bash
# Basic installation
pip install raganything
# With optional dependencies for extended format support:
pip install 'raganything[all]' # All optional features
pip install 'raganything[image]' # Image format conversion (BMP, TIFF, GIF, WebP)
pip install 'raganything[text]' # Text file processing (TXT, MD)
pip install 'raganything[image,text]' # Multiple features
```
#### Option 2: Install from Source
```bash
git clone https://github.com/HKUDS/RAG-Anything.git
cd RAG-Anything
pip install -e .
# With optional dependencies
pip install -e '.[all]'
```
#### Optional Dependencies
- **`[image]`** - Enables processing of BMP, TIFF, GIF, WebP image formats (requires Pillow)
- **`[text]`** - Enables processing of TXT and MD files (requires ReportLab)
- **`[all]`** - Includes all Python optional dependencies
> **⚠️ Office Document Processing Requirements:**
> - Office documents (.doc, .docx, .ppt, .pptx, .xls, .xlsx) require **LibreOffice** installation
> - Download from [LibreOffice official website](https://www.libreoffice.org/download/download/)
> - **Windows**: Download installer from official website
> - **macOS**: `brew install --cask libreoffice`
> - **Ubuntu/Debian**: `sudo apt-get install libreoffice`
> - **CentOS/RHEL**: `sudo yum install libreoffice`
**Check MinerU installation:**
```bash
# Verify installation
mineru --version
# Check if properly configured
python -c "from raganything import RAGAnything; rag = RAGAnything(); print('✅ MinerU installed properly' if rag.check_mineru_installation() else '❌ MinerU installation issue')"
```
Models are downloaded automatically on first use. For manual download, refer to [MinerU Model Source Configuration](https://github.com/opendatalab/MinerU/blob/master/README.md#22-model-source-configuration).
### Usage Examples
#### 1. End-to-End Document Processing
```python
import asyncio
from raganything import RAGAnything, RAGAnythingConfig
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
async def main():
# Set up API configuration
api_key = "your-api-key"
base_url = "your-base-url" # Optional
# Create RAGAnything configuration
config = RAGAnythingConfig(
working_dir="./rag_storage",
parser="mineru", # Parser selection: mineru or docling
parse_method="auto", # Parse method: auto, ocr, or txt
enable_image_processing=True,
enable_table_processing=True,
enable_equation_processing=True,
)
# Define LLM model function
def llm_model_func(prompt, system_prompt=None, history_messages=[], **kwargs):
return openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=api_key,
base_url=base_url,
**kwargs,
)
# Define vision model function for image processing
def vision_model_func(
prompt, system_prompt=None, history_messages=[], image_data=None, messages=None, **kwargs
):
# If messages format is provided (for multimodal VLM enhanced query), use it directly
if messages:
return openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=messages,
api_key=api_key,
base_url=base_url,
**kwargs,
)
# Traditional single image format
elif image_data:
return openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=[
{"role": "system", "content": system_prompt}
if system_prompt
else None,
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
},
},
],
}
if image_data
else {"role": "user", "content": prompt},
],
api_key=api_key,
base_url=base_url,
**kwargs,
)
# Pure text format
else:
return llm_model_func(prompt, system_prompt, history_messages, **kwargs)
# Define embedding function
embedding_func = EmbeddingFunc(
embedding_dim=3072,
max_token_size=8192,
func=lambda texts: openai_embed(
texts,
model="text-embedding-3-large",
api_key=api_key,
base_url=base_url,
),
)
# Initialize RAGAnything
rag = RAGAnything(
config=config,
llm_model_func=llm_model_func,
vision_model_func=vision_model_func,
embedding_func=embedding_func,
)
# Process a document
await rag.process_document_complete(
file_path="path/to/your/document.pdf",
output_dir="./output",
parse_method="auto"
)
# Query the processed content
# Pure text query - for basic knowledge base search
text_result = await rag.aquery(
"What are the main findings shown in the figures and tables?",
mode="hybrid"
)
print("Text query result:", text_result)
# Multimodal query with specific multimodal content
multimodal_result = await rag.aquery_with_multimodal(
"Explain this formula and its relevance to the document content",
multimodal_content=[{
"type": "equation",
"latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}",
"equation_caption": "Document relevance probability"
}],
mode="hybrid"
)
print("Multimodal query result:", multimodal_result)
if __name__ == "__main__":
asyncio.run(main())
```
#### 2. Direct Multimodal Content Processing
```python
import asyncio
from lightrag import LightRAG
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
from raganything.modalprocessors import ImageModalProcessor, TableModalProcessor
async def process_multimodal_content():
# Set up API configuration
api_key = "your-api-key"
base_url = "your-base-url" # Optional
# Initialize LightRAG
rag = LightRAG(
working_dir="./rag_storage",
llm_model_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=api_key,
base_url=base_url,
**kwargs,
),
embedding_func=EmbeddingFunc(
embedding_dim=3072,
max_token_size=8192,
func=lambda texts: openai_embed(
texts,
model="text-embedding-3-large",
api_key=api_key,
base_url=base_url,
),
)
)
await rag.initialize_storages()
# Process an image
image_processor = ImageModalProcessor(
lightrag=rag,
modal_caption_func=lambda prompt, system_prompt=None, history_messages=[], image_data=None, **kwargs: openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=[
{"role": "system", "content": system_prompt} if system_prompt else None,
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
]} if image_data else {"role": "user", "content": prompt}
],
api_key=api_key,
base_url=base_url,
**kwargs,
) if image_data else openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=api_key,
base_url=base_url,
**kwargs,
)
)
image_content = {
"img_path": "path/to/image.jpg",
"img_caption": ["Figure 1: Experimental results"],
"img_footnote": ["Data collected in 2024"]
}
description, entity_info = await image_processor.process_multimodal_content(
modal_content=image_content,
content_type="image",
file_path="research_paper.pdf",
entity_name="Experimental Results Figure"
)
# Process a table
table_processor = TableModalProcessor(
lightrag=rag,
modal_caption_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=api_key,
base_url=base_url,
**kwargs,
)
)
table_content = {
"table_body": """
| Method | Accuracy | F1-Score |
|--------|----------|----------|
| RAGAnything | 95.2% | 0.94 |
| Baseline | 87.3% | 0.85 |
""",
"table_caption": ["Performance Comparison"],
"table_footnote": ["Results on test dataset"]
}
description, entity_info = await table_processor.process_multimodal_content(
modal_content=table_content,
content_type="table",
file_path="research_paper.pdf",
entity_name="Performance Results Table"
)
if __name__ == "__main__":
asyncio.run(process_multimodal_content())
```
#### 3. Batch Processing
```python
# Process multiple documents
await rag.process_folder_complete(
folder_path="./documents",
output_dir="./output",
file_extensions=[".pdf", ".docx", ".pptx"],
recursive=True,
max_workers=4
)
```
#### 4. Custom Modal Processors
```python
from raganything.modalprocessors import GenericModalProcessor
class CustomModalProcessor(GenericModalProcessor):
async def process_multimodal_content(self, modal_content, content_type, file_path, entity_name):
# Your custom processing logic
enhanced_description = await self.analyze_custom_content(modal_content)
entity_info = self.create_custom_entity(enhanced_description, entity_name)
return await self._create_entity_and_chunk(enhanced_description, entity_info, file_path)
```
#### 5. Query Options
RAG-Anything provides three types of query methods:
**Pure Text Queries** - Direct knowledge base search using LightRAG:
```python
# Different query modes for text queries
text_result_hybrid = await rag.aquery("Your question", mode="hybrid")
text_result_local = await rag.aquery("Your question", mode="local")
text_result_global = await rag.aquery("Your question", mode="global")
text_result_naive = await rag.aquery("Your question", mode="naive")
# Synchronous version
sync_text_result = rag.query("Your question", mode="hybrid")
```
**VLM Enhanced Queries** - Automatically analyze images in retrieved context using VLM:
```python
# VLM enhanced query (automatically enabled when vision_model_func is provided)
vlm_result = await rag.aquery(
"Analyze the charts and figures in the document",
mode="hybrid"
# vlm_enhanced=True is automatically set when vision_model_func is available
)
# Manually control VLM enhancement
vlm_enabled = await rag.aquery(
"What do the images show in this document?",
mode="hybrid",
vlm_enhanced=True # Force enable VLM enhancement
)
vlm_disabled = await rag.aquery(
"What do the images show in this document?",
mode="hybrid",
vlm_enhanced=False # Force disable VLM enhancement
)
# When documents contain images, VLM can see and analyze them directly
# The system will automatically:
# 1. Retrieve relevant context containing image paths
# 2. Load and encode images as base64
# 3. Send both text context and images to VLM for comprehensive analysis
```
**Multimodal Queries** - Enhanced queries with specific multimodal content analysis:
```python
# Query with table data
table_result = await rag.aquery_with_multimodal(
"Compare these performance metrics with the document content",
multimodal_content=[{
"type": "table",
"table_data": """Method,Accuracy,Speed
RAGAnything,95.2%,120ms
Traditional,87.3%,180ms""",
"table_caption": "Performance comparison"
}],
mode="hybrid"
)
# Query with equation content
equation_result = await rag.aquery_with_multimodal(
"Explain this formula and its relevance to the document content",
multimodal_content=[{
"type": "equation",
"latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}",
"equation_caption": "Document relevance probability"
}],
mode="hybrid"
)
```
#### 6. Loading Existing LightRAG Instance
```python
import asyncio
from raganything import RAGAnything, RAGAnythingConfig
from lightrag import LightRAG
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.kg.shared_storage import initialize_pipeline_status
from lightrag.utils import EmbeddingFunc
import os
async def load_existing_lightrag():
# Set up API configuration
api_key = "your-api-key"
base_url = "your-base-url" # Optional
# First, create or load existing LightRAG instance
lightrag_working_dir = "./existing_lightrag_storage"
# Check if previous LightRAG instance exists
if os.path.exists(lightrag_working_dir) and os.listdir(lightrag_working_dir):
print("✅ Found existing LightRAG instance, loading...")
else:
print("❌ No existing LightRAG instance found, will create new one")
# Create/load LightRAG instance with your configuration
lightrag_instance = LightRAG(
working_dir=lightrag_working_dir,
llm_model_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=api_key,
base_url=base_url,
**kwargs,
),
embedding_func=EmbeddingFunc(
embedding_dim=3072,
max_token_size=8192,
func=lambda texts: openai_embed(
texts,
model="text-embedding-3-large",
api_key=api_key,
base_url=base_url,
),
)
)
# Initialize storage (this will load existing data if available)
await lightrag_instance.initialize_storages()
await initialize_pipeline_status()
# Define vision model function for image processing
def vision_model_func(
prompt, system_prompt=None, history_messages=[], image_data=None, messages=None, **kwargs
):
# If messages format is provided (for multimodal VLM enhanced query), use it directly
if messages:
return openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=messages,
api_key=api_key,
base_url=base_url,
**kwargs,
)
# Traditional single image format
elif image_data:
return openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=[
{"role": "system", "content": system_prompt}
if system_prompt
else None,
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
},
},
],
}
if image_data
else {"role": "user", "content": prompt},
],
api_key=api_key,
base_url=base_url,
**kwargs,
)
# Pure text format
else:
return lightrag_instance.llm_model_func(prompt, system_prompt, history_messages, **kwargs)
# Now use existing LightRAG instance to initialize RAGAnything
rag = RAGAnything(
lightrag=lightrag_instance, # Pass existing LightRAG instance
vision_model_func=vision_model_func,
# Note: working_dir, llm_model_func, embedding_func, etc. are inherited from lightrag_instance
)
# Query existing knowledge base
result = await rag.aquery(
"What data has been processed in this LightRAG instance?",
mode="hybrid"
)
print("Query result:", result)
# Add new multimodal document to existing LightRAG instance
await rag.process_document_complete(
file_path="path/to/new/multimodal_document.pdf",
output_dir="./output"
)
if __name__ == "__main__":
asyncio.run(load_existing_lightrag())
```
#### 7. Direct Content List Insertion
For scenarios where you already have a pre-parsed content list (e.g., from external parsers or previous processing), you can directly insert it into RAGAnything without document parsing:
```python
import asyncio
from raganything import RAGAnything, RAGAnythingConfig
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
async def insert_content_list_example():
# Set up API configuration
api_key = "your-api-key"
base_url = "your-base-url" # Optional
# Create RAGAnything configuration
config = RAGAnythingConfig(
working_dir="./rag_storage",
enable_image_processing=True,
enable_table_processing=True,
enable_equation_processing=True,
)
# Define model functions
def llm_model_func(prompt, system_prompt=None, history_messages=[], **kwargs):
return openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=api_key,
base_url=base_url,
**kwargs,
)
def vision_model_func(prompt, system_prompt=None, history_messages=[], image_data=None, messages=None, **kwargs):
# If messages format is provided (for multimodal VLM enhanced query), use it directly
if messages:
return openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=messages,
api_key=api_key,
base_url=base_url,
**kwargs,
)
# Traditional single image format
elif image_data:
return openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=[
{"role": "system", "content": system_prompt} if system_prompt else None,
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
],
} if image_data else {"role": "user", "content": prompt},
],
api_key=api_key,
base_url=base_url,
**kwargs,
)
# Pure text format
else:
return llm_model_func(prompt, system_prompt, history_messages, **kwargs)
embedding_func = EmbeddingFunc(
embedding_dim=3072,
max_token_size=8192,
func=lambda texts: openai_embed(
texts,
model="text-embedding-3-large",
api_key=api_key,
base_url=base_url,
),
)
# Initialize RAGAnything
rag = RAGAnything(
config=config,
llm_model_func=llm_model_func,
vision_model_func=vision_model_func,
embedding_func=embedding_func,
)
# Example: Pre-parsed content list from external source
content_list = [
{
"type": "text",
"text": "This is the introduction section of our research paper.",
"page_idx": 0 # Page number where this content appears
},
{
"type": "image",
"img_path": "/absolute/path/to/figure1.jpg", # IMPORTANT: Use absolute path
"img_caption": ["Figure 1: System Architecture"],
"img_footnote": ["Source: Authors' original design"],
"page_idx": 1 # Page number where this image appears
},
{
"type": "table",
"table_body": "| Method | Accuracy | F1-Score |\n|--------|----------|----------|\n| Ours | 95.2% | 0.94 |\n| Baseline | 87.3% | 0.85 |",
"table_caption": ["Table 1: Performance Comparison"],
"table_footnote": ["Results on test dataset"],
"page_idx": 2 # Page number where this table appears
},
{
"type": "equation",
"latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}",
"text": "Document relevance probability formula",
"page_idx": 3 # Page number where this equation appears
},
{
"type": "text",
"text": "In conclusion, our method demonstrates superior performance across all metrics.",
"page_idx": 4 # Page number where this content appears
}
]
# Insert the content list directly
await rag.insert_content_list(
content_list=content_list,
file_path="research_paper.pdf", # Reference file name for citation
split_by_character=None, # Optional text splitting
split_by_character_only=False, # Optional text splitting mode
doc_id=None, # Optional custom document ID (will be auto-generated if not provided)
display_stats=True # Show content statistics
)
# Query the inserted content
result = await rag.aquery(
"What are the key findings and performance metrics mentioned in the research?",
mode="hybrid"
)
print("Query result:", result)
# You can also insert multiple content lists with different document IDs
another_content_list = [
{
"type": "text",
"text": "This is content from another document.",
"page_idx": 0 # Page number where this content appears
},
{
"type": "table",
"table_body": "| Feature | Value |\n|---------|-------|\n| Speed | Fast |\n| Accuracy | High |",
"table_caption": ["Feature Comparison"],
"page_idx": 1 # Page number where this table appears
}
]
await rag.insert_content_list(
content_list=another_content_list,
file_path="another_document.pdf",
doc_id="custom-doc-id-123" # Custom document ID
)
if __name__ == "__main__":
asyncio.run(insert_content_list_example())
```
**Content List Format:**
The `content_list` should follow the standard format with each item being a dictionary containing:
- **Text content**: `{"type": "text", "text": "content text", "page_idx": 0}`
- **Image content**: `{"type": "image", "img_path": "/absolute/path/to/image.jpg", "img_caption": ["caption"], "img_footnote": ["note"], "page_idx": 1}`
- **Table content**: `{"type": "table", "table_body": "markdown table", "table_caption": ["caption"], "table_footnote": ["note"], "page_idx": 2}`
- **Equation content**: `{"type": "equation", "latex": "LaTeX formula", "text": "description", "page_idx": 3}`
- **Generic content**: `{"type": "custom_type", "content": "any content", "page_idx": 4}`
**Important Notes:**
- **`img_path`**: Must be an absolute path to the image file (e.g., `/home/user/images/chart.jpg` or `C:\Users\user\images\chart.jpg`)
- **`page_idx`**: Represents the page number where the content appears in the original document (0-based indexing)
- **Content ordering**: Items are processed in the order they appear in the list
This method is particularly useful when:
- You have content from external parsers (non-MinerU/Docling)
- You want to process programmatically generated content
- You need to insert content from multiple sources into a single knowledge base
- You have cached parsing results that you want to reuse
---
## 🛠️ Examples
*Practical Implementation Demos*
The `examples/` directory contains comprehensive usage examples:
- **`raganything_example.py`**: End-to-end document processing with MinerU
- **`modalprocessors_example.py`**: Direct multimodal content processing
- **`office_document_test.py`**: Office document parsing test with MinerU (no API key required)
- **`image_format_test.py`**: Image format parsing test with MinerU (no API key required)
- **`text_format_test.py`**: Text format parsing test with MinerU (no API key required)
**Run examples:**
```bash
# End-to-end processing with parser selection
python examples/raganything_example.py path/to/document.pdf --api-key YOUR_API_KEY --parser mineru
# Direct modal processing
python examples/modalprocessors_example.py --api-key YOUR_API_KEY
# Office document parsing test (MinerU only)
python examples/office_document_test.py --file path/to/document.docx
# Image format parsing test (MinerU only)
python examples/image_format_test.py --file path/to/image.bmp
# Text format parsing test (MinerU only)
python examples/text_format_test.py --file path/to/document.md
# Check LibreOffice installation
python examples/office_document_test.py --check-libreoffice --file dummy
# Check PIL/Pillow installation
python examples/image_format_test.py --check-pillow --file dummy
# Check ReportLab installation
python examples/text_format_test.py --check-reportlab --file dummy
```
---
## 🔧 Configuration
*System Optimization Parameters*
### Environment Variables
Create a `.env` file (refer to `.env.example`):
```bash
OPENAI_API_KEY=your_openai_api_key
OPENAI_BASE_URL=your_base_url # Optional
OUTPUT_DIR=./output # Default output directory for parsed documents
PARSER=mineru # Parser selection: mineru or docling
PARSE_METHOD=auto # Parse method: auto, ocr, or txt
```
**Note:** For backward compatibility, legacy environment variable names are still supported:
- `MINERU_PARSE_METHOD` is deprecated, please use `PARSE_METHOD`
> **Note**: API keys are only required for full RAG processing with LLM integration. The parsing test files (`office_document_test.py` and `image_format_test.py`) only test parser functionality and do not require API keys.
### Parser Configuration
RAGAnything now supports multiple parsers, each with specific advantages:
#### MinerU Parser
- Supports PDF, images, Office documents, and more formats
- Powerful OCR and table extraction capabilities
- GPU acceleration support
#### Docling Parser
- Optimized for Office documents and HTML files
- Better document structure preservation
- Native support for multiple Office formats
### MinerU Configuration
```bash
# MinerU 2.0 uses command-line parameters instead of config files
# Check available options:
mineru --help
# Common configurations:
mineru -p input.pdf -o output_dir -m auto # Automatic parsing mode
mineru -p input.pdf -o output_dir -m ocr # OCR-focused parsing
mineru -p input.pdf -o output_dir -b pipeline --device cuda # GPU acceleration
```
You can also configure parsing through RAGAnything parameters:
```python
# Basic parsing configuration with parser selection
await rag.process_document_complete(
file_path="document.pdf",
output_dir="./output/",
parse_method="auto", # or "ocr", "txt"
parser="mineru" # Optional: "mineru" or "docling"
)
# Advanced parsing configuration with special parameters
await rag.process_document_complete(
file_path="document.pdf",
output_dir="./output/",
parse_method="auto", # Parsing method: "auto", "ocr", "txt"
parser="mineru", # Parser selection: "mineru" or "docling"
# MinerU special parameters - all supported kwargs:
lang="ch", # Document language for OCR optimization (e.g., "ch", "en", "ja")
device="cuda:0", # Inference device: "cpu", "cuda", "cuda:0", "npu", "mps"
start_page=0, # Starting page number (0-based, for PDF)
end_page=10, # Ending page number (0-based, for PDF)
formula=True, # Enable formula parsing
table=True, # Enable table parsing
backend="pipeline", # Parsing backend: pipeline|vlm-transformers|vlm-sglang-engine|vlm-sglang-client.
source="huggingface", # Model source: "huggingface", "modelscope", "local"
# vlm_url="http://127.0.0.1:3000" # Service address when using backend=vlm-sglang-client
# Standard RAGAnything parameters
display_stats=True, # Display content statistics
split_by_character=None, # Optional character to split text by
doc_id=None # Optional document ID
)
```
> **Note**: MinerU 2.0 no longer uses the `magic-pdf.json` configuration file. All settings are now passed as command-line parameters or function arguments. RAG-Anything now supports multiple document parsers - you can choose between MinerU and Docling based on your needs.
### Processing Requirements
Different content types require specific optional dependencies:
- **Office Documents** (.doc, .docx, .ppt, .pptx, .xls, .xlsx): Install [LibreOffice](https://www.libreoffice.org/download/download/)
- **Extended Image Formats** (.bmp, .tiff, .gif, .webp): Install with `pip install raganything[image]`
- **Text Files** (.txt, .md): Install with `pip install raganything[text]`
> **📋 Quick Install**: Use `pip install raganything[all]` to enable all format support (Python dependencies only - LibreOffice still needs separate installation)
---
## 🧪 Supported Content Types
### Document Formats
- **PDFs** - Research papers, reports, presentations
- **Office Documents** - DOC, DOCX, PPT, PPTX, XLS, XLSX
- **Images** - JPG, PNG, BMP, TIFF, GIF, WebP
- **Text Files** - TXT, MD
### Multimodal Elements
- **Images** - Photographs, diagrams, charts, screenshots
- **Tables** - Data tables, comparison charts, statistical summaries
- **Equations** - Mathematical formulas in LaTeX format
- **Generic Content** - Custom content types via extensible processors
*For installation of format-specific dependencies, see the [Configuration](#-configuration) section.*
---
## 📖 Citation
*Academic Reference*
If you find RAG-Anything useful in your research, please cite our paper:
```bibtex
@article{guo2024lightrag,
title={LightRAG: Simple and Fast Retrieval-Augmented Generation},
author={Zirui Guo and Lianghao Xia and Yanhua Yu and Tu Ao and Chao Huang},
year={2024},
eprint={2410.05779},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
---
## 🔗 Related Projects
*Ecosystem & Extensions*
---
## ⭐ Star History
*Community Growth Trajectory*
---
## 🤝 Contribution
*Join the Innovation*
We thank all our contributors for their valuable contributions.
---
⭐
Thank you for visiting RAG-Anything!
⭐
Building the Future of Multimodal AI




